
Digital imaging has come a long way since the first consumer cameras began converting light into pixels. In the early days, photographers and designers worked within strict technical boundaries, limited by resolution, storage capacity, and the blunt instruments of early editing software. Adjusting a photo meant manually pushing sliders, applying filters, or painstakingly retouching images pixel by pixel.
Then artificial intelligence entered the picture, and everything changed. Over the past two decades, AI has quietly and then quite dramatically reshaped how we capture, process, and interact with images.
What once required hours of expert labor can now be accomplished in seconds, and what was once technically impossible is now within reach of anyone with a smartphone or a browser tab. This article traces that transformation, from the earliest algorithmic tools to the generative models redefining visual creativity today.
The Early Days of Digital Imaging
The shift from film to digital sensors in the 1990s democratized photography in ways that were genuinely unprecedented. Software like Adobe Photoshop became the industry standard, offering layers, masks, and adjustment tools that gave users an enormous degree of control. But all of this was entirely manual. The software did exactly what the user told it to do, nothing more.
The limitations were obvious. Removing a complex background required painstaking manual selection. Restoring a damaged old photograph meant hours of cloning and patching. Upscaling a low-resolution image simply stretched the pixels and produced a blurry result. The tools were powerful by the standards of their time, but they had no understanding of what they were looking at.
Machine Learning Enters the Frame
The introduction of machine learning into image processing marked a fundamental shift in approach. Rather than following explicit rules written by programmers, machine learning models learn patterns from vast datasets and develop their own internal representations of visual concepts.
Convolutional Neural Networks, or CNNs, were particularly transformative. These architectures detect edges, textures, shapes, and eventually high-level features like faces or objects, meaning software could now actually recognize the content of an image rather than simply manipulating its pixels.
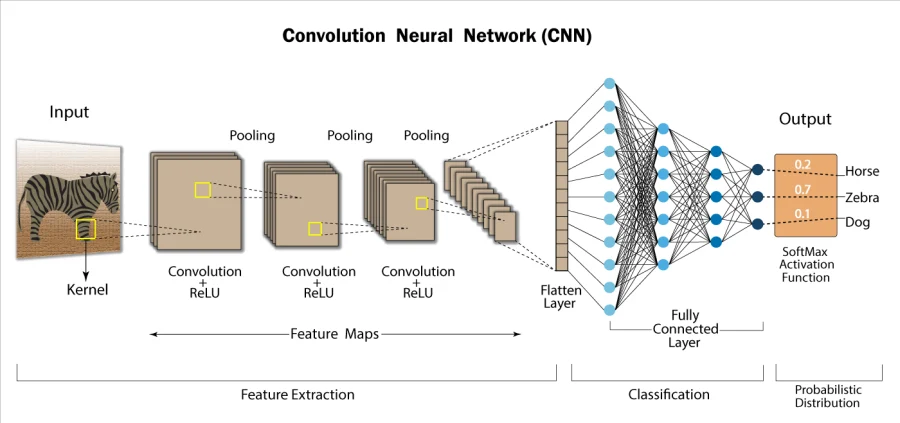
Early practical applications included noise reduction algorithms that could distinguish between genuine image detail and digital noise, intelligent upscaling models, and auto-tagging systems that could label thousands of photos by subject matter in moments.
These were not incremental improvements. They represented a new category of capability entirely.
The Generative AI Revolution and Photo Restoration
Generative Models and Creative AI
The next major leap came with generative models, AI systems capable of creating visual content rather than just analyzing or enhancing it. Generative Adversarial Networks (GANs), introduced by Ian Goodfellow in 2014, pitted two neural networks against each other until the generator produced results realistic enough to fool the critic.
The results were startling. GANs could generate photorealistic faces of people who had never existed, transfer artistic styles onto modern photographs, and synthesize entirely new visual content from learned patterns.
Then came diffusion models, the architecture behind tools like DALL·E, Midjourney, and Stable Diffusion. These models can generate extraordinarily detailed visuals from simple text descriptions, with implications for creative industries, advertising, and entertainment that are still unfolding.
Photo Restoration as a Generative Application
It was within this context that AI photo restoration emerged as one of the most compelling applications of the technology, offering the ability to repair scratches, reconstruct missing areas, reduce fading, and colorize black and white images with a degree of realism that manual methods could never achieve.
The same generative capabilities that allow a model to invent a believable face can be applied to fill in the missing parts of a damaged photograph, guided by surrounding context and trained knowledge of how images should look.
AI in Modern Professional and Consumer Photography
Computational Photography
Computational photography has become one of the defining features of modern smartphones. Apple, Google, and Samsung have invested heavily in AI-powered camera systems that go far beyond what the physical hardware alone could produce.
When a modern smartphone captures a portrait, it runs real-time AI models that analyze depth, identify subjects, and apply sophisticated rendering decisions in milliseconds, often surpassing what a much larger camera would produce in the same conditions.
Post-Processing and Real-Time Enhancements
Professional editing software has integrated AI-driven post-processing that automates tasks once requiring significant expertise. Selecting a subject, removing unwanted background elements, adjusting lighting with an understanding of facial structure, these are now accessible with a single click.
Real-time enhancements have also become standard across consumer devices. Scene detection adjusts camera settings automatically, HDR processing combines multiple exposures to preserve detail in highlights and shadows, and portrait mode uses depth estimation to create convincing shallow depth of field effects on hardware that would not naturally produce them.
Challenges and Controversies
Deepfakes and Misinformation
Deepfakes represent perhaps the most widely discussed concern. The same generative technology that can restore a beloved old photograph can also fabricate convincing footage of public figures saying things they never said.
As the technology becomes more accessible, the potential for misuse in political manipulation and misinformation grows accordingly.
Copyright and Authenticity
Copyright and ownership present another set of unresolved questions. Generative AI models are trained on vast datasets of existing images, many created by artists who were not consulted and receive no compensation when their work influences AI output. Legal frameworks are still struggling to catch up.
Photojournalism is actively grappling with where to draw the line between legitimate enhancement and misleading fabrication, a debate with no easy answers.
The Future of AI in Digital Imaging
The trajectory of AI in digital imaging points toward capabilities that would have seemed like science fiction a decade ago. Three-dimensional content generation is advancing rapidly, with models learning to produce consistent 3D scenes from 2D inputs. Video synthesis is progressing in parallel, with AI systems generating short clips from text descriptions and modifying existing footage in sophisticated ways.
The convergence of AI imaging with augmented and virtual reality represents another frontier with enormous potential. As AR and VR hardware matures, real-time content generation and adaptation will become central to making those experiences believable and responsive.
The relationship between human creativity and AI capability is still being defined, and the most interesting work at this frontier is not about replacement but collaboration. Artists and photographers are finding ways to use generative tools as a new kind of medium, one that responds to creative intention while contributing its own unexpected possibilities.
Conclusion
The evolution of AI in digital imaging is a story about expanding what is possible. From the manual pixel-pushing of early editing software to generative models that can conjure entire worlds from a sentence, each chapter has brought new capabilities, new creative opportunities, and new responsibilities.
The technology will continue to advance, and the most important decisions ahead are not technical ones. They are about how we choose to use these remarkable tools, and what values we bring to that process.
Read Next

1440p Resolution: The Definitive Guide to QHD

What is My Screen Resolution

QLED Technology: The Science Behind the Brilliance

LG UltraGear 24GQ50F-B Review: 1920×1080 165Hz 1ms MBR FreeSync Premium; Essential Features Without Breaking the Bank

MLA OLED: Brighter Displays with Micro Lens Array

HD vs HDR: Differences and Benefits

Mini LED vs OLED: Which Display Technology Reigns Supreme?

4K Resolution: Ultimate Experience for TVs and Monitors

HDR10 vs 4K: Showdown for Superior Visuals

HDR vs OLED – What Sets Them Apart?

HDR10 vs HLG: Comparing HDR Technologies

1440p vs 1080p: Which Resolution Should You Choose?

Direct Lit vs Edge Lit vs Full Array: Decoding TV Backlight Technology
